The removeConsole: true bug that hid every other bug

The removeConsole: true bug that hid every other bug
Our first attempt at memory-optimizing Linkgo on Railway shipped, crashed, got reverted, and left us staring at a Node process that had failed silently. No stack trace. No scheduler error. Nothing. The deploy logs ended cleanly and the container exited with a non-zero code. That's it.
It took us a second pass through the code — and a senior code review — to find what was actually breaking. The most dramatic finding wasn't a memory leak. It was that we had been operating in production with every console.error call quietly removed by the build.
The problem
Linkgo runs Next.js on Railway with five long-lived async subsystems on one Node process: a marketing scheduler, two campaign workers, a publisher, and a token refresh loop. Memory was creeping up over hours, so we wrote a "Phase 1+2" branch that did the standard things — switch to the Next standalone bundle, kill an unused Prisma "optimized" wrapper, drop a setInterval that nobody ever cleared, simplify the build.
It deployed. The container started. Then sometime after boot it terminated with no log line we could correlate. We rolled back, ate the regression, and pulled in a senior reviewer.
The first finding from that review was not subtle:
// next.config.js (before)
compiler: {
removeConsole: process.env.NODE_ENV === 'production',
},
The bare-true form of removeConsole strips every console.* call at compile time. Including console.error. Including the ones in instrumentation.ts that were supposed to log scheduler initialization failures. We had been deploying to production with the equivalent of 2>/dev/null on every error path.
That explained the silence. The schedulers were almost certainly throwing during startup; we just couldn't see it.
Why it happened
The Next.js docs are explicit that removeConsole: true removes all console calls and that you should pass { exclude: ['error'] } to keep error logging. But the option has been around long enough that a lot of starter configs ship with the bare boolean, and once it's in your next.config.js it's invisible — the symptom is "nothing in the logs", which looks like "nothing went wrong" until it doesn't.
The fix is one line:
// next.config.js (after)
compiler: {
removeConsole: process.env.NODE_ENV === 'production'
? { exclude: ['error', 'warn'] }
: false,
},
Once that landed, every other finding in the senior review surfaced naturally — because we could finally see what the process was doing.
What we tried first
The first instinct, before we found the log-stripping, had been to look for the memory leak more aggressively: instrument heap snapshots, hunt down the rogue setInterval, blame Prisma. Most of that was wrong. The schedulers weren't leaking; they were crashing on startup and taking the process with them. Memory wasn't the bug; observability was.
The fix
Three reliability fixes shipped alongside the removeConsole change. None are exotic. All of them required the logs to come back before we could even tell they were needed.
Top-level handlers in instrumentation.ts. Five long-lived async subsystems mean five places where an unhandled rejection can take the process down. Node 15+ terminates on unhandled rejection by default. We register handlers before any scheduler import:
process.on('unhandledRejection', (reason) => {
console.error('[INSTRUMENTATION] UNHANDLED REJECTION:', reason)
})
process.on('uncaughtException', (err) => {
console.error('[INSTRUMENTATION] UNCAUGHT EXCEPTION:', err)
if (!isShuttingDown.value) {
isShuttingDown.value = true
process.exit(1)
}
})
The unhandledRejection handler logs and lets the process keep running. For uncaughtException we still exit (Node's documented guidance), but we exit after one error log lands. Pre-fix, neither handler existed and neither log line would have rendered anyway.
The Prisma global guard was the wrong way around. Pre-fix:
export const prisma = globalForPrisma.prisma ?? prismaClientSingleton()
if (process.env.NODE_ENV !== 'production') globalForPrisma.prisma = prisma
The !== 'production' was meant to avoid HMR weirdness in development. What it actually did was guarantee that in production, every module re-evaluation (different webpack chunks importing this file, etc.) skipped the cache and constructed a fresh PrismaClient — a fresh 10-connection pool every time. Silent connection leak, no warning. The fix is to cache unconditionally:
globalForPrisma.prisma = prisma
if (!globalForPrisma.prismaListenersRegistered) {
process.on('beforeExit', handleShutdown)
process.on('SIGINT', handleShutdown)
process.on('SIGTERM', handleShutdown)
globalForPrisma.prismaListenersRegistered = true
}
The listener-guard exists because re-evaluation also re-registered shutdown listeners and tripped Node's default 10-listener cap with a MaxListenersExceededWarning — the only warning we did still see, because warnings go to a different code path than console.error.
Detached promise in tokenRefreshScheduler.start(). The initial checkAllTokens() was fired-and-forgotten so start() could stay synchronous. A rejection there used to escape as an unhandled rejection — fine in dev, fatal in prod under Node 15+. Now:
this.checkAllTokens().catch((err) => {
console.error('Token refresh initial check failed:', err);
});
The two prisma.tokenRefreshLog.create() writes inside notifyRefreshSuccess / notifyRefreshFailure got the same try/catch wrap — a logging failure is the worst possible reason to take the whole process down.
Before and after
We don't have a clean memory before/after to publish yet — the deploy is too fresh to compare against the previous week's chart. What we do have is the boot-time test:
| Scenario | Before | After |
|---|---|---|
| Boot with database unreachable | container exits, no useful log | Ready in 107ms, healthcheck 200, all five schedulers fail with full stack traces logged, process survives 13s+ at idle |
console.error calls in compiled instrumentation.js |
0 | 1 (the Failed to initialize line we wrote) |
The boot-survives-DB-down case is a strict superset of the senior reviewer's planned repro (an empty social_media_tokens table) and was the actual gating test for merge.
What we learned
A few things we'll carry forward, in roughly the order of how surprised we were:
removeConsole: trueis a footgun. If you want it on at all, write it as{ exclude: ['error', 'warn'] }. Add a lint rule if you want to be sure no one regresses it.- Silence is data. A production process exiting with no log line is itself a signal — about the log path, not about the failure. We now treat "no error logged" as a class of bug rather than as evidence of correctness.
globalThiscaches need to be unconditional. TheNODE_ENV !== 'production'guard around a singleton cache reads as "be careful in dev" but actually disables the cache exactly where it matters.unhandledRejectionhandlers are mandatory for any service with detached promises. Especially with multiple long-lived schedulers — one rejection in any of them is a process crash.
What's next
Two threads still open:
- 24-hour memory chart compared to pre-deploy. We'll know by the end of the week whether the standalone bundle + the deleted unused code actually moved the resident-set number, or whether the win was purely about not crashing every few hours.
- A small lint rule for
next.config.jsthat fails on bareremoveConsole: true. Not glamorous; would have saved us a week.
The PR for everything above is linkgo#1 if you want the full context.
Try Linkgo
Linkgo turns your link-in-bio into a smart shop — try it at linkgo.dev.
Frequently Asked Questions
What caused the silent failures in the Linkgo production deployment?
The silent failures were caused by the `removeConsole: true` setting in Next.js, which stripped all console calls including `console.error`. This prevented error logs from appearing, making it impossible to see startup crashes or other errors.
How can you configure Next.js to remove console logs but keep error and warning messages?
Instead of using `removeConsole: true`, configure it as `removeConsole: { exclude: ['error', 'warn'] }` in `next.config.js`. This removes all console calls except for `console.error` and `console.warn`, preserving critical error logging in production.
Why is it important to have `unhandledRejection` and `uncaughtException` handlers in Node.js services?
These handlers catch unhandled promise rejections and exceptions, allowing the service to log errors before exiting or continuing safely. Without them, Node.js 15+ terminates the process silently on unhandled rejections, making debugging difficult.
What was wrong with the Prisma client caching in the original Linkgo code?
The Prisma client cache was disabled in production due to a condition that only cached in non-production environments. This caused multiple Prisma clients and connection pools to be created, leading to silent connection leaks and resource exhaustion.
What lessons were learned from the `removeConsole: true` bug in Linkgo?
Key lessons include avoiding bare `removeConsole: true` to prevent losing error logs, treating absence of logs as a bug signal, ensuring global caches are unconditional, and mandating unhandled rejection handlers in services with asynchronous subsystems.
Continue reading
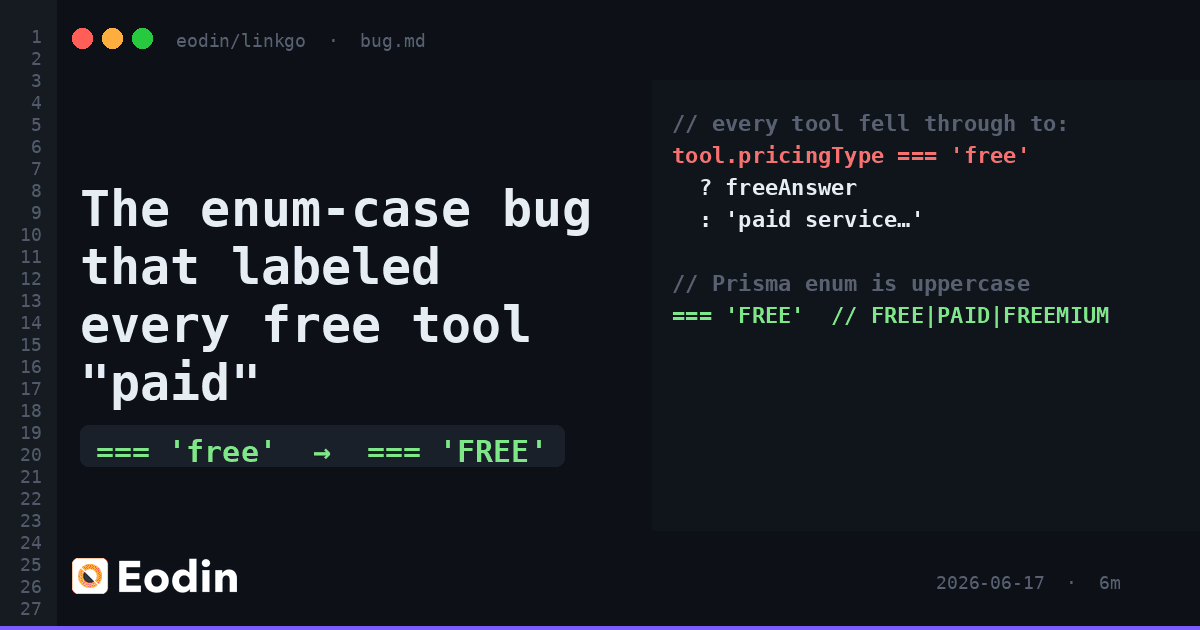
The enum-case bug that labeled every free tool "paid"
Every tool in our directory told Google the same thing about price: it was paid. Free tools too. The cause was a lowercase enum comparison that never matched.
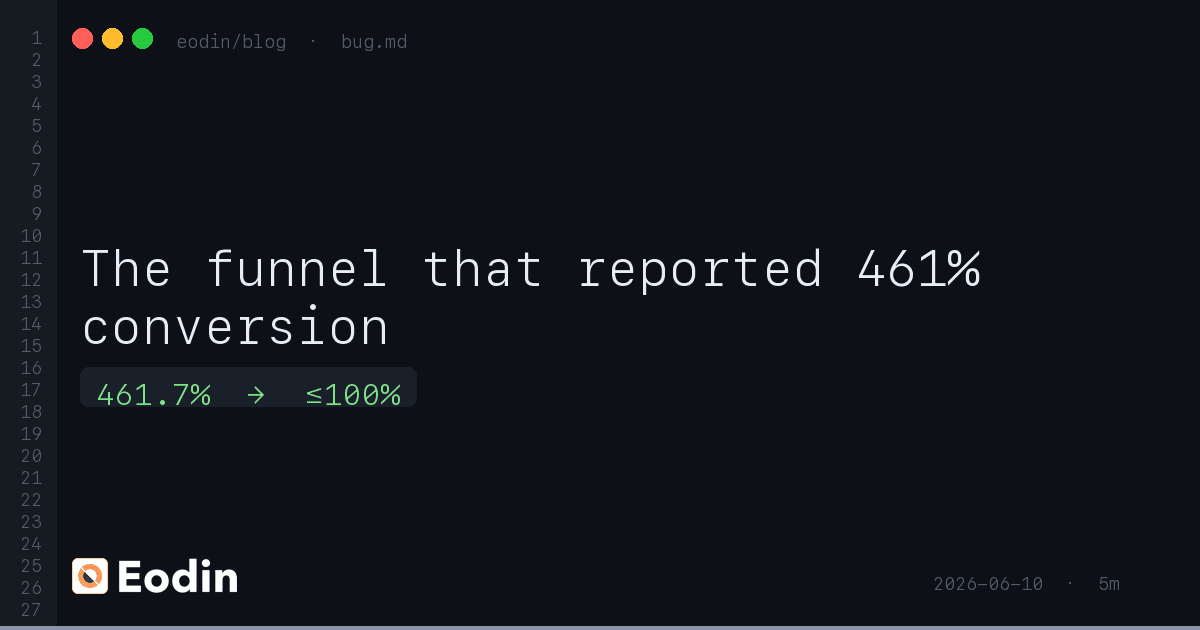
The funnel that reported 461% conversion
Our analytics funnel reported a step converting at 461.7% with a negative drop rate — because it counted event rows, not unique devices. Here is the fix.

How we removed fingerprinting from our deep-link attribution
A walkthrough of replacing our SHA256 device-fingerprint matcher with deterministic Play Install Referrer clickIds on Android and a guarded IP fallback on iOS.