What happens to a connection pool when you fork a Celery worker (spoiler: nothing good)

One of our internal admin dashboards started throwing Prisma's P2037 — Too many database connections opened. The dashboard had been fine for months, the data volume hadn't changed, and no one had recently touched the page. Classic setup for a weird afternoon.
pg_stat_activity told a story we didn't expect: 96 idle, 1 active. Not a runaway query, not a deadlock, not a leak in the usual sense. The database was holding 96 sessions open that nobody was using. Our Railway Postgres plan caps max_connections at 100. We had four slots of headroom.
Why so many idle connections?
Our backend runs two services that talk to the same Postgres:
- A Next.js/Prisma backend with
connection_limit=5. Singleton client. Boring and correct. - A Python/SQLAlchemy AI service that runs both a FastAPI API and a Celery worker (
--concurrency=4, prefork).
The AI service was doing three things wrong at the same time, and each one multiplied the next.
1. Two engines for one database. db_service.py created a SQLAlchemy engine. prompt_loader.py — an unrelated module we'd added months later for loading LLM prompts from the DB — created a second engine pointing at the same URL. Two engines mean two independent connection pools. Every LLM call touched both.
2. Default pool settings. Neither engine specified pool_size or max_overflow, so both used SQLAlchemy's defaults: pool_size=5, max_overflow=10. That's a ceiling of 15 connections per engine per process. Two engines × 15 = 30 per Python process.
3. Fork without dispose(). Celery's prefork mode starts a master, imports your code (which creates the engines at import time), then fork()s four children. Those children inherit the master's open socket file descriptors. Postgres sees them as live sessions. SQLAlchemy, from each child's point of view, doesn't know they were inherited — so when the child runs its first query, it opens a new connection, leaving the inherited socket as an idle zombie.
Multiply it out: 1 master + 4 children = 5 processes. 5 × 2 engines × 15 = 150 theoretical connections from a single ai-worker container. Our plan's limit is 100. The idle-96 number suddenly made sense.
The fix was three small changes
First, we dropped the duplicate engine. prompt_loader.py now imports the shared one:
# before
from sqlalchemy import create_engine, text
from app.config import settings
engine = create_engine(settings.sqlalchemy_database_url)
# after
from sqlalchemy import text
from app.services.db_service import engine
That single change halved the per-process ceiling from 30 to 15.
Second, we capped the shared pool:
engine = create_engine(
settings.sqlalchemy_database_url,
pool_pre_ping=True,
pool_recycle=300,
pool_size=2,
max_overflow=3,
pool_timeout=10,
)
With --concurrency=4 and worker_prefetch_multiplier=1, each child is running exactly one task at a time. A task might checkout one connection for the work itself and one for the usage log; pool_size=2 covers the steady state and max_overflow=3 absorbs bursts. pool_timeout=10 makes exhaustion fail fast and loud instead of quietly queuing — if we're saturated we want to know, not stall.
Third — and this is the one that isn't obvious — we added a worker_process_init signal handler:
from celery.signals import worker_process_init
@worker_process_init.connect
def _reset_db_pool_after_fork(**_kwargs):
from app.services.db_service import engine
engine.dispose(close=False)
The close=False matters. A plain dispose() would close the inherited sockets, but those sockets are also live in the parent — closing them would yank the rug out from under the master's own work. close=False tells SQLAlchemy "drop these handles without closing them; let the OS clean up when the parent exits or the FDs are garbage-collected." Each child then opens its own fresh pool on first use. This is the recommended pattern in the SQLAlchemy 2.x docs for fork-based concurrency, and it's easy to miss because dispose() on its own sounds like the right call.
Before and after
| Before | After | |
|---|---|---|
| Engines per process | 2 | 1 |
| Pool ceiling per process | 30 | 5 |
| ai-worker container max | ~150 (theoretical) | 25 |
Observed pg_stat_activity idle |
96 | 6–14 |
The P2037 errors stopped. The dashboard stopped hanging. The connection count graph dropped off a cliff and flattened — and it stayed flat across the next few deploys, which is how we confirmed the fork-inheritance theory was right and not just a bandwidth lull.
What we took away
The obvious lesson is "don't fork with a populated connection pool." The less obvious one is that SQLAlchemy's defaults are tuned for a monolithic API process, not for a Celery prefork worker running on a platform with a hard connection cap. Nothing about the defaults is wrong — they're just wrong for this deployment shape. Any time you multiply pool_size by something (worker processes, gunicorn workers, container replicas), check the product against your database's ceiling before you ship.
The other takeaway: the duplicate engine had existed for months. It only became a problem when traffic grew enough for the idle-session math to close in on the 100 cap. Configuration bugs are patient. They wait for you.
Next on the list is putting PgBouncer in transaction-pooling mode in front of Railway Postgres, so the pool math stops being so load-bearing in our application code. With transaction pooling, every worker can keep a generous local pool and the bouncer multiplexes those into a much smaller pool of real Postgres connections — meaning future scaling decisions (adding a worker tier, bumping --concurrency, running two ai-worker containers) stop being connection-budgeting exercises. But the three-change fix above bought us all the headroom we needed this quarter, and it was shipped in an afternoon. Good return on a 306-line diff — and a reminder that when a database looks like it's leaking, it's worth checking whether your framework just handed it 96 copies of the same socket.
Plori turns your travel photos into a story — without making you write one.
Frequently Asked Questions
Why does forking a Celery worker cause issues with database connection pools?
Forking a Celery worker inherits the parent's open database connections, causing each child process to hold onto idle connections that SQLAlchemy doesn't recognize. This results in 'zombie' connections that inflate the total number of active sessions, potentially exceeding database connection limits.
How can duplicate SQLAlchemy engines affect database connection usage?
Having multiple SQLAlchemy engines pointing to the same database creates independent connection pools for each engine. This multiplies the total number of connections used per process, increasing the risk of hitting the database's maximum connection limit.
What is the recommended way to reset SQLAlchemy connection pools after a Celery worker forks?
Use a `worker_process_init` signal handler to call `engine.dispose(close=False)` in each child process. This drops inherited connections without closing them, allowing each child to open fresh connections safely without disrupting the parent process.
How should connection pool sizes be configured for Celery workers with prefork concurrency?
Pool sizes should be set conservatively to account for the number of worker processes and concurrency. For example, setting `pool_size=2` and `max_overflow=3` per engine ensures enough connections for steady and burst workloads without exceeding database limits.
What are the benefits of using PgBouncer in transaction-pooling mode with Celery workers?
PgBouncer in transaction-pooling mode multiplexes many client connections into fewer actual database connections, allowing workers to maintain larger local pools without exhausting the database's connection limit. This simplifies scaling and reduces connection management complexity in the application.
Continue reading
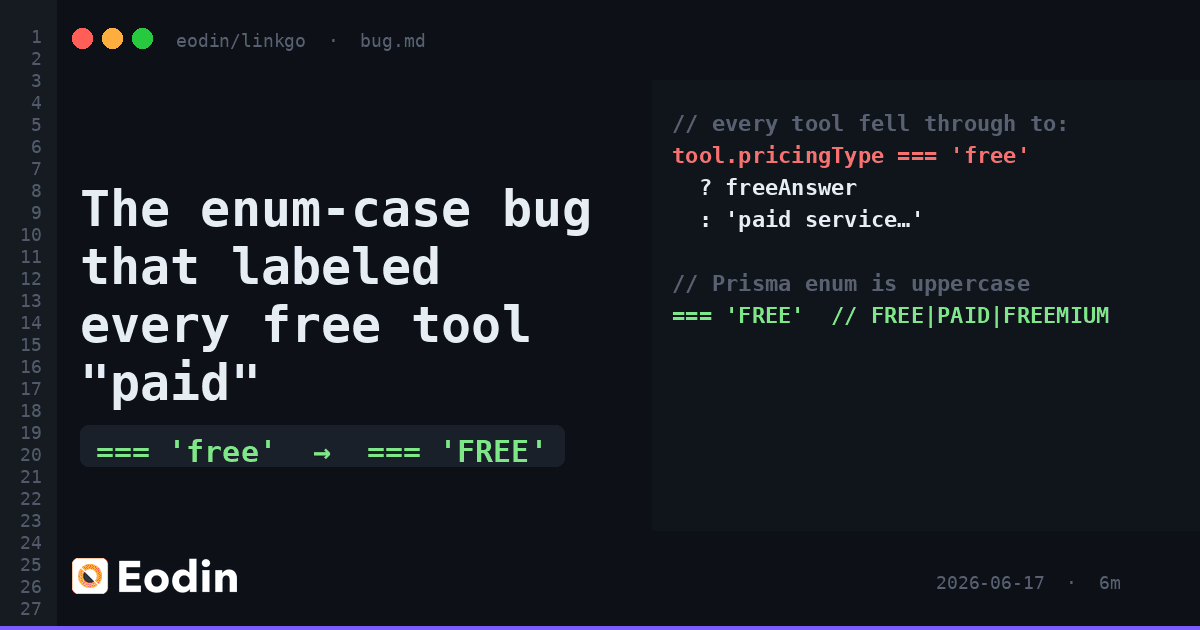
The enum-case bug that labeled every free tool "paid"
Every tool in our directory told Google the same thing about price: it was paid. Free tools too. The cause was a lowercase enum comparison that never matched.
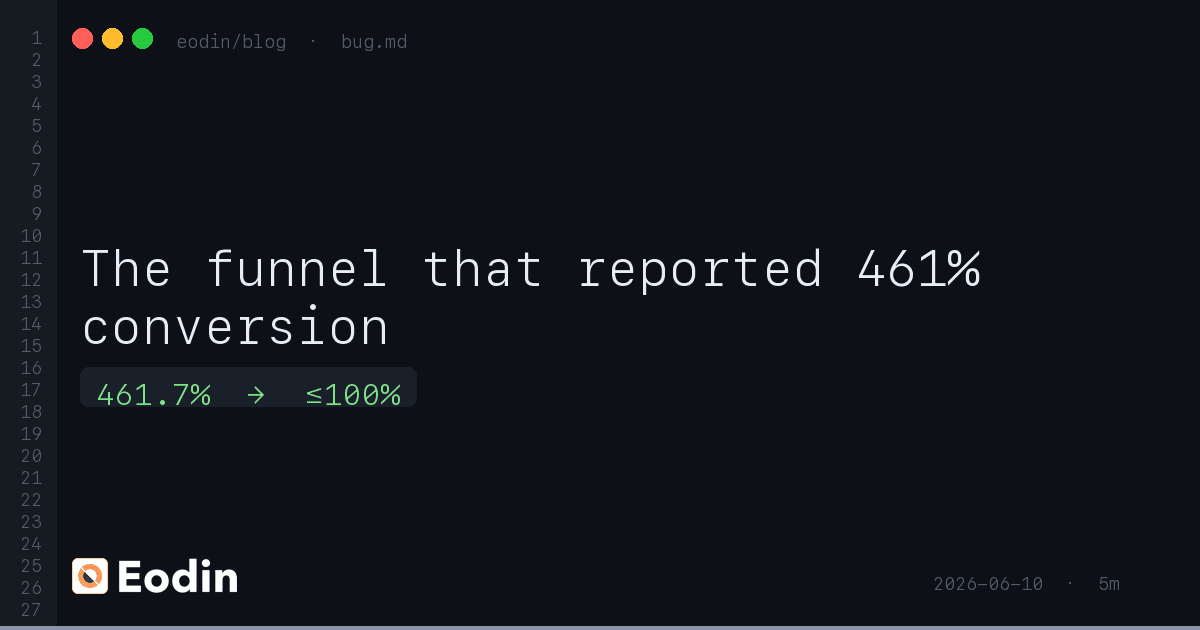
The funnel that reported 461% conversion
Our analytics funnel reported a step converting at 461.7% with a negative drop rate — because it counted event rows, not unique devices. Here is the fix.

How we removed fingerprinting from our deep-link attribution
A walkthrough of replacing our SHA256 device-fingerprint matcher with deterministic Play Install Referrer clickIds on Android and a guarded IP fallback on iOS.